title: CNN 加速器
date: 2024-04-28 20:28:55
tags: [cnn accelerator]
YOLOv5

Pytorch
https://pytorch.org/tutorials/
网络架构选择与修改
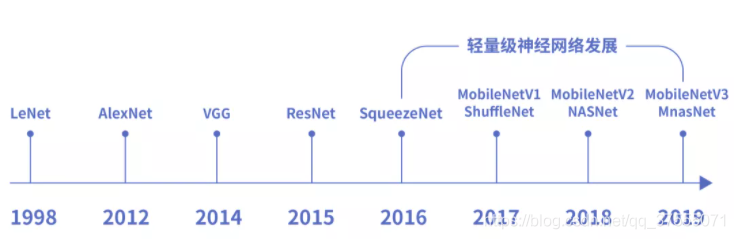
mobileNetV1
由Google提出,其核心是深度可分离卷积。不仅可以降低模型计算复杂度,而且可以大大降低模型大小,适合应用在真实的移动端应用场景。
模型
为移动端部署目标检测模型确实需要考虑模型的尺寸和计算复杂度。以下是一些比较流行的轻量级目标检测卷积神经网络:
YOLO系列:
- YOLOv5: https://github.com/ultralytics/yolov5
- YOLOv4: https://github.com/AlexeyAB/darknet
YOLO系列模型在保持较高精度的同时,模型尺寸和计算复杂度相对较低,适合移动端部署。
SSD (单Shot多框检测器):
- MobileNetSSD: https://github.com/chuanqi305/MobileNetSSD
- RFSoD: https://github.com/songjianPI/RFSoD
这些模型基于移动设备优化的MobileNet骨干网络,模型尺寸小,运算效率较高。
EfficientDet:
- EfficientDet-Lite: https://github.com/google/automl/tree/master/efficientdet
EfficientDet系列是Google开源的一系列高效目标检测模型,其中EfficientDet-Lite专门针对移动设备优化。
- EfficientDet-Lite: https://github.com/google/automl/tree/master/efficientdet
FCOS (全卷积单阶段物体检测):
- Ultralight FCOS: https://github.com/ReighBay/Ultralight-FCOS
基于FCOS设计的Ultralight FCOS通过模型压缩和网路设计加速,在保持较高精度的同时显著降低了模型尺寸和计算量。
- Ultralight FCOS: https://github.com/ReighBay/Ultralight-FCOS
这些模型通过特定的网络设计、模型压缩等策略达到了在移动设备上的高效部署,但其中也存在一定的权衡,需要根据具体场景的精度和速度要求进行选择。
注意力机制(Attention Mechanism)是深度学习领域中一种重要的技术,它通过计算一个输入序列中不同位置的元素对输出的重要程度,从而学会更好地关注对预测任务有用的部分。
注意力机制最早被应用于机器翻译任务中,后来也广泛用于计算机视觉、自然语言处理等领域。主要思想是在计算输出时,对不同位置的输入赋予不同的权重,使模型能够专注于更重要的部分。
注意力机制主要包括以下几个步骤:
- 获取查询(Query)向量和键(Keys)向量:查询向量代表当前状态,键向量代表要关注的输入序列。
- 计算注意力分数(Attention Scores):通过某种方法(如点乘或加性)计算查询向量与所有键向量的相似性分数。
- 归一化注意力分数:对注意力分数进行归一化处理(如softmax),得到注意力权重。
- 加权求和:使用注意力权重对值向量(Value Vectors)进行加权求和,得到最终的输出向量。
不同类型的注意力机制主要区别在于计算注意力分数的方法和输入表示的方式上。一些常见的注意力机制包括:
- 加性注意力(Additive Attention):计算查询和键之间的加性相似性。
- 点乘注意力(Dot-Product Attention):计算查询和键向量的点乘作为相似性分数(如Transformer中的multi-head注意力)。
- 多头注意力(Multi-Head Attention):允许注意力机制从不同的子空间获取信息。
- 自注意力(Self-Attention):查询、键、值向量来自同一个输入序列,常用于捕获长距离依赖关系。
注意力机制通过动态关注输入中对预测任务更有用的部分,显著提高了深度学习模型在各种任务上的性能,是目前许多优秀模型的关键技术之一。
除了注意力机制之外,还有一些其他有用的机制被广泛应用于目标检测任务中,以提高检测性能。以下是一些常用的机制:
- 锚框(Anchor Boxes) 锚框机制将图像划分为多个区域,对每个区域生成多个预先设定形状和比例的锚框,然后根据锚框与真实边界框的重合程度预测目标。这种机制常用于一阶段目标检测器,如Faster R-CNN。
- 特征金字塔(Feature Pyramid Networks, FPN) FPN融合了不同尺度的特征图,使用横向连接融合高层语义特征和底层细节特征,增强了目标检测在不同尺度上的能力。
- 先验框回归(Bounding Box Regression) 通过回归预测一个先验框与真实边界框的偏移量,从而精细修正先验框的位置和尺寸,提高目标定位的精度。
- 非极大值抑制(Non-Maximum Suppression, NMS) NMS通过消除重叠目标框,留下置信度最高的那些框,从而去除重复检测的结果。
- 上下文增强(Context Enhancement) 利用目标周围区域的上下文信息去增强目标特征表示,提高小目标和遮挡目标的检测性能。
- 学习隔离表示(Learnable Embedding Representation) 通过学习像素级的语义嵌入表示,提高对目标的识别和检测。
- 数据增广(Data Augmentation) 使用各种图像变换手段(翻转、裁剪、扭曲等)在训练时生成更多不同的样本,增强模型的泛化性能。
- 级联结构(Cascade Structure) 采用多阶段级联机制,使得每个阶段的分类器和回归器都可以专注于比上个阶段更难但范围更小的样本区域,提高检测准确率。
这些机制可以单独或组合使用,并针对不同的目标检测任务有优化和调整。通过引入这些机制,目标检测模型可以获得更好的检测精度和鲁棒性。
对于识别不同类型的血细胞,一些常用的深度学习网络包括:
- 卷积神经网络(CNN)
- CNN擅长从图像中提取特征,可以用于血细胞图像分类任务。典型的网络如AlexNet、VGGNet、ResNet等都可以应用于此问题。
- 可以考虑使用较浅层的CNN,如LeNet等,因为血细胞图像相对简单,无需过于深层的网络。
- 全卷积网络(FCN)
- FCN无需将输入图像固定尺寸,可以对任意尺寸输入进行分割和像素级分类。
- 适合血细胞检测和分割任务,可以同时识别和定位不同类型的细胞。
- U-Net
- U-Net是一种常用的医学图像分割网络,具有编码器-解码器结构。
- 通过跳跃连接融合不同尺度特征,效果好,常用于血细胞等细粒度对象分割。
- Mask R-CNN
- 基于Faster R-CNN的实例分割网络,可同时实现目标检测和像素级分割。
- 适合同时检测和分类不同类型的细胞。
- 小型网络
- 如MobileNet、SqueezeNet等,计算量小,适合移动端和嵌入式应用场景部署。
- 可用于快速血细胞分类,满足低功耗和实时性要求。
在使用这些网络时,数据预处理、数据增强、正则化、细调超参数等都是非常重要的。此外医学影像往往数据量较小,可以考虑迁移学习等方法来提升性能。具体选择哪种网络,需要权衡精度、速度和部署环境的需求。
在资源受限环针对血细胞识别这一具体任务,有以下几种方式可以提高网络的性能:
- 数据增强 由于医疗图像数据通常较为稀缺,因此可以通过数据增强的方式扩充训练集,常用的数据增强操作包括旋转、翻转、缩放、裁剪、噪声添加等。这有助于提高模型的泛化能力。
- 微调预训练模型 在医疗图像数据集上从头训练模型需要大量数据,一种可行方式是利用在大型数据集(如ImageNet)上预训练的模型,通过微调的方式将其迁移到医疗任务上。这可以极大缩短收敛时间并提高性能。
- 集成学习 将多个不同模型的预测结果集成,可以显著提升性能。常用的集成方法包括Bagging、Boosting、投票等。对于不同的预测模型,也可以考虑级联或加权平均的方式进行融合。
- 注意力机制 引入注意力机制有助于模型学习聚焦图像的关键区域,对细胞类型的识别非常有帮助,例如可以使用SENet或非局部模块等。
- 体系结构改进 根据任务特点对网络架构进行改进,如采用U-Net的编码器-解码器结构、加入空洞卷积等操作,以提取更加有效的特征。
- 优化器和损失函数 选择合适的优化器(如Adam)和损失函数(交叉熵、Focal Loss等)对模型训练也很重要。
- 硬件加速 充分利用GPU、TPU等加速硬件,可以大幅提高模型训练和部署的效率。
- 人工干预 人工引导和修正模型识别结果,也是医疗领域常用的手段,可以构建交互式识别系统。
综上所述,通过数据增强、模型微调和集成、注意力机制等多管齐下,结合领域知识对网络进行优化和改造,可以有效提高血细胞识别的性能。
境如移动端或嵌入式设备中,通常需要一些小型化的目标检测模型,以权衡模型大小、计算量和检测精度。以下是一些常用的小型目标检测网络:
YOLO 系列
:
- YOLOv4-Tiny: 小型版本的 YOLOv4 网络,只有 6.9M 参数。
- YOLOv5s: YOLOv5 中最小的版本,参数量 7.5M。
SSD 系列
:
- MobileNet-SSD: 采用 MobileNet 作为主干网络,具有很小的模型尺寸(6M 左右)。
- SqueezeNet-SSD: 基于 SqueezeNet 的轻量级 SSD 网络。
单级检测器
:
- Single Shot MultiBox Detector (SSD)
- RetinaNet
Two-Stage 检测器
:
- Faster R-CNN (Tiny Versions)
- FCOS (Fully Convolutional One-Stage Object Detection)
特定领域优化网络
:
- PVANET: 专为人体检测而设计的小型网络。
- M2Det: 针对工业上的小型缺陷检测任务。
基于 MobileNet / ShuffleNet 的检测网络
:
- MobileNetV3-SSD / ShuffleNetV2-SSD
- MnasFPN (Neural Architecture Search)
这些网络一般都在 1M~10M 参数量的范围内,通过模型压缩、网络设计等策略达到了较小的模型尺寸和计算量,可以在资源受限环境下实现实时的目标检测。但它们也存在一定的精度损失,需要根据应用场景的具体要求进行权衡选择。
2015
全卷积网络(Fully Convolutional Networks, FCN)
FCN模型最早发表于2015年的论文《Fully Convolutional Networks for Semantic Segmentation》,该论文由加州大学伯克利分校的Jonathan Long、Evan Shelhamer、Trevor Darrell等人撰写,发表于IEEE计算机协会的计算机视觉与模式识别(CVPR)顶级会议。
将现有的卷积神经网络改造成全卷积的结构,可以接受任意尺寸的输入图像,并对每个像素点输出对应的预测结果,从而可用于语义分割任务。
创新点:
1、将全连接层转化为卷积层,接受任意大小输入。
2、使用反卷积层进行上采样,获得与输入分辨率相同的输出。
3、增加跳级结构,融合多尺度特征信息。
很多后续工作如U-Net、DeepLab等都是基于FCN提出的创新思路发展而来。因此,FCN可以说是计算机视觉语义分割发展史上具有里程碑意义的工作。
除了MobileNet和SqueezeNet之外,还有一些适合部署的轻量级网络模型结构,特别是用于目标检测任务的。以下是一些常见的轻量级目标检测模型:
YOLO系列:You Only Look Once(YOLO)是一系列快速目标检测模型,其中YOLOv3和YOLOv4在保持较高检测准确率的同时,具有较快的推理速度。它们的网络结构相对较简单,适合在资源有限的设备上部署。
Tiny YOLO:Tiny YOLO是YOLO系列的一个子集,专门设计用于轻量级目标检测。它相对于标准的YOLO模型来说,具有更少的层和参数,因此更适合部署在嵌入式设备上。
SSD-MobileNet:SSD(Single Shot MultiBox Detector)是另一个常用的目标检测模型,结合了目标检测和图像分类的功能。SSD-MobileNet结合了MobileNet作为特征提取器和SSD作为检测头,实现了在移动设备上的高效目标检测。
EfficientDet:EfficientDet是谷歌提出的一种高效的目标检测模型系列,它们通过使用EfficientNet作为特征提取器,并结合轻量级的检测头,实现了在资源受限的环境下高效的目标检测。
Pelee:Pelee是另一个轻量级目标检测模型,它专门设计用于移动设备和嵌入式系统。Pelee模型采用密集连接的设计,同时结合了轻量级的特征提取器和检测头,具有较高的检测精度和较快的推理速度。
这些轻量级目标检测模型结构都在追求在移动设备等资源受限环境下实现高效的目标检测性能,它们的设计都考虑了模型大小、推理速度和准确率之间的平衡。选择适合的模型应根据具体应用场景的需求和设备资源情况进行评估。
快速降采样
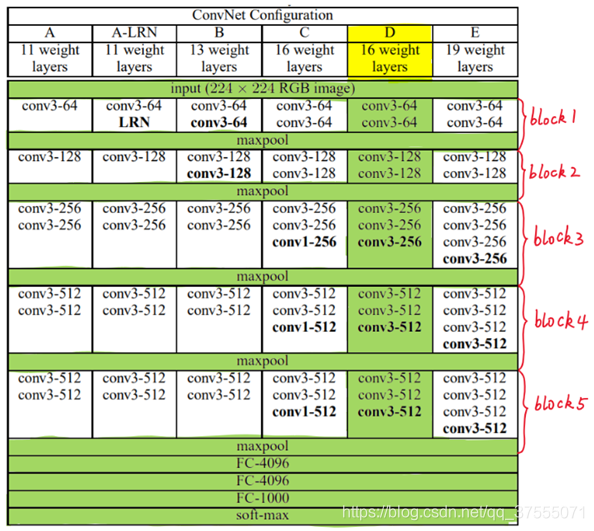
VGG16
YOLOv5
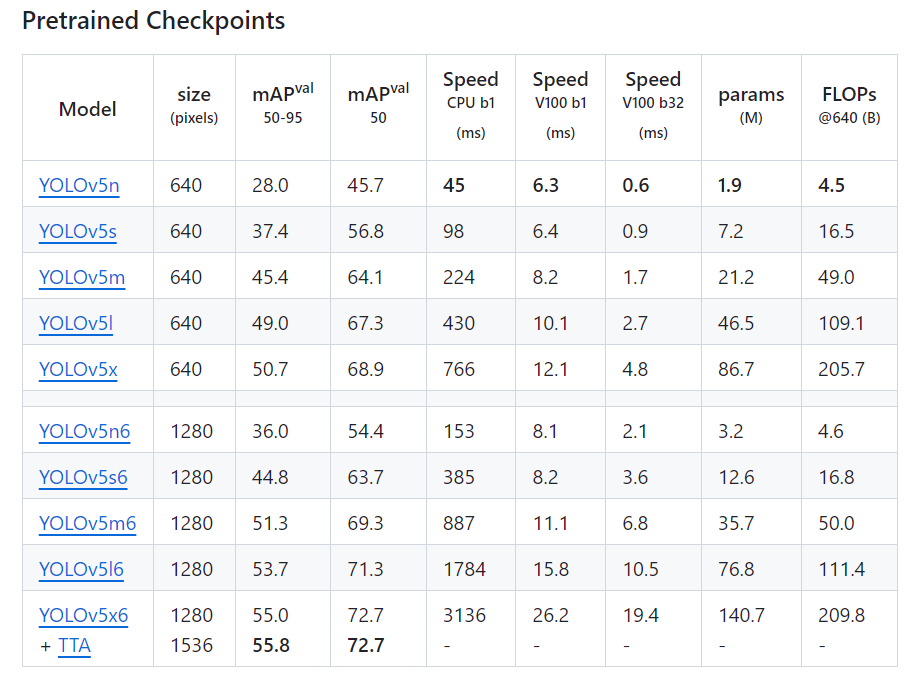
关于YOLOv5网络结构:
对于识别不同类型的血细胞,一些常用的深度学习网络包括:
- 卷积神经网络(CNN)
- CNN擅长从图像中提取特征,可以用于血细胞图像分类任务。典型的网络如AlexNet、VGGNet、ResNet等都可以应用于此问题。
- 可以考虑使用较浅层的CNN,如LeNet等,因为血细胞图像相对简单,无需过于深层的网络。
- 全卷积网络(FCN)
- FCN无需将输入图像固定尺寸,可以对任意尺寸输入进行分割和像素级分类。
- 适合血细胞检测和分割任务,可以同时识别和定位不同类型的细胞。
- U-Net
- U-Net是一种常用的医学图像分割网络,具有编码器-解码器结构。
- 通过跳跃连接融合不同尺度特征,效果好,常用于血细胞等细粒度对象分割。
- Mask R-CNN
- 基于Faster R-CNN的实例分割网络,可同时实现目标检测和像素级分割。
- 适合同时检测和分类不同类型的细胞。
- 小型网络
- 如MobileNet、SqueezeNet等,计算量小,适合移动端和嵌入式应用场景部署。
- 可用于快速血细胞分类,满足低功耗和实时性要求。
在使用这些网络时,数据预处理、数据增强、正则化、细调超参数等都是非常重要的。此外医学影像往往数据量较小,可以考虑迁移学习等方法来提升性能。具体选择哪种网络,需要权衡精度、速度和部署环境的需求。
针对血细胞识别这一具体任务,有以下几种方式可以提高网络的性能:
- 数据增强 由于医疗图像数据通常较为稀缺,因此可以通过数据增强的方式扩充训练集,常用的数据增强操作包括旋转、翻转、缩放、裁剪、噪声添加等。这有助于提高模型的泛化能力。
- 微调预训练模型 在医疗图像数据集上从头训练模型需要大量数据,一种可行方式是利用在大型数据集(如ImageNet)上预训练的模型,通过微调的方式将其迁移到医疗任务上。这可以极大缩短收敛时间并提高性能。
- 集成学习 将多个不同模型的预测结果集成,可以显著提升性能。常用的集成方法包括Bagging、Boosting、投票等。对于不同的预测模型,也可以考虑级联或加权平均的方式进行融合。
- 注意力机制 引入注意力机制有助于模型学习聚焦图像的关键区域,对细胞类型的识别非常有帮助,例如可以使用SENet或非局部模块等。
- 体系结构改进 根据任务特点对网络架构进行改进,如采用U-Net的编码器-解码器结构、加入空洞卷积等操作,以提取更加有效的特征。
- 优化器和损失函数 选择合适的优化器(如Adam)和损失函数(交叉熵、Focal Loss等)对模型训练也很重要。
- 硬件加速 充分利用GPU、TPU等加速硬件,可以大幅提高模型训练和部署的效率。
- 人工干预 人工引导和修正模型识别结果,也是医疗领域常用的手段,可以构建交互式识别系统。
综上所述,通过数据增强、模型微调和集成、注意力机制等多管齐下,结合领域知识对网络进行优化和改造,可以有效提高血细胞识别的性能。
YoloX
目标检测网络YoloX介绍及实现—深度学习十六
YOLOX网络结构详解
如何写出轻量化的目标检测算法?
NanoDet
目标检测模型NanoDet(超轻量,速度很快)介绍和PyTorch版本实践
YOLO之外的另一选择,手机端97FPS的Anchor-Free目标检测模型NanoDet现已开源~
8bit\4bit\2bit量化
空洞思想
性能指标
图像与权重数据的转换
YoloR